
- Research
- 13/04/2020

Alternative hardware for artificial intelligence
Supercomputers outperform humans in more and more areas, but their energy consumption is astronomically high. That is why we can’t escape switching to radically different hardware, inspired by our own brain, analog perhaps, with light instead of electrons, or even based on DNA or quantum bits. Cursor spoke to five ambitious TU/e scientists about their vision and plans.
Even though the term artificial intelligence (AI) was first coined in the 1950’s already, it took a long time before computer systems with certain learning and problem-solving capabilities grew into something more than nice toys in a lab. However, it seems that by now we really find ourselves at the beginning of the era of AI. The combination of fast-growing computation power and the even faster growing amount of data that can be fed into AI systems makes AI a dynamic and influential research area: AI is rapidly developing into a technology with the potential to radically change our society.
Nevertheless, the AI motor already seems to be showing signs of malfunctioning: since a number of years, computing power has ceased to grow at an exponential rate, whereas we continue to generate more data every two years than everything we produced before. That is why energy consumption will be the major obstacle on the path towards even smarter AI: since the computing power per chip grows at an insufficient rate, ever increasing numbers of processors are linked together in so-called massive parallel systems. These usually consist of GPU’s, the Graphic Processing Units known from video cards in gaming computers. Self-learning algorithms can run on these GPU’s, but against high energy costs.
To give an idea: the power consumption of the AlphaGo computer, which in 2016 defeatedLee Sedol, world champion of the strategic board game Go, was estimated at 1 megawatt – fifty thousand times more than his human opponent.And that’s just a relatively limited supercomputer. The current most powerful supercomputer, IBM’s Summit (150 FLOP/s), uses 13 megawatts – enough for thirteen thousand households – and is considered energy-efficient. In short: compared to the human brain, AI is extremely inefficient. And this while the human brain has increasingly become a source of inspiration for how we want computers to function, as demonstrated by the popularity of so-called ‘neural networks’ for AI applications.
That is why it’s necessary to find alternatives to the current hardware based on silicon transistors, on which our pcs have been successfully running their ‘classic’ algorithms for decades. True artificial intelligence makes other kinds of demands on the architecture of hardware: analog perhaps instead of digital, with light instead of electrons, and made of organic material instead of silicon. DNA might be more logical for medical applications, and what does the quantum computer have to offer? Researchers at TU/e, too, are working on all of these alternative forms of computer hardware.
1. Alternatives in silicon electronics

Even with ‘standard’ electronic silicon technology there is still some gain to be made by designing hardware specifically for artificial neural networks. Henk Corporaal, professor in the Electronic Systems group, has been working on computer architecture for about thirty-five years. “In the past, the focus was mainly on computing power per area, but now energy usage per operation has become a very important parameter as well,” he says. The problem lies mainly in the (temporary) storage of data in the computer’s memory. Storing a bit in a local memory costs twice as much energy as a basic addition, Corporaal shows, and sending data wireless and subsequently storing it in the cloud even costs fifty million times as much.
Neural networks
In ‘machine learning,’ an AI system is fed labeled training data, with which it learns to discern categories. This way, the computer can learn the difference between images of dogs and cats, for example (or learn the right moves in a board game), without an explicit description of the differences between these two animals. Artificial neural networks, which simulate the architecture of the human brain, prove to be very good at performing these tasks. Neural networks consist of a few layers of ‘neurons,’ which are connected via links of variable strength. During the training process, the strength (or 'weight') of these links is adapted for a specific task, so that the network is able to classify new input. This last step is called ‘inference.’ Neural networks can be programmed on standard computer chips, but in principle, hardware specifically designed for this purpose is much more efficient.
This immediately makes it clear why training neural networks costs so much energy: when determining the proper parameters (the ‘weights’ that indicate how strongly connected the artificial neurons are), the values require constant feedback and therefore have to be stored temporarily.
For this reason, local computing and storage is also important from an environmental (and financial) perspective – exactly the opposite of the current trend in ‘cloud computing’ and online services. That’s why researchers are working on alternative architectures, in which memory elements are placed close to the processors in order to minimize the data transport on the chip as well.
In addition, parallel computing, which is done already in GPU’s, is currently being further perfected, Corporaal says. “Companies like NVIDIA are working on so-called ‘tensor cores’ in which matrix products are computed in one go. To make that more energy efficient, these special processors do not work with 64 or 32 bits, like we are used to in our personal computers, but with 16 or 8 bits even. That turns out to be sufficiently accurate for practically every application with neural networks, and it’s much more efficient as well.”
Each bit you don’t need to transport or store immediately yields an energy gain. That is why eventually moving towards systems that work with numbers of a single bit is the holy grail, according to the professor. “We work on that at TU/e as well. Of course you lose accuracy, it’s no free lunch, and you need to compensate for that one way or another, for example by working with a larger number of artificial neurons.”
Adding instead of multiplying
Computing with numbers consisting of a single bit (‘0’ or ‘1’) has its own peculiarities, Corporaal explains. “Instead of multiplying, you can use XNOR circuits and add the outcomes of that. That’s again more energy efficient than multiplying. To give an idea: the Summit supercomputer uses 65 picojoule per operation. When you go to 8 bits, you use approximately 1 picojoule. The current record with 1 bit is twenty femtojoule per operation; that’s fifty times more energy efficient. We’ve now presented a proposal with which we want to arrive at 1 femtojoule. But even then our brains are more efficient.”
Our brain is less accurate than conventional computers, and that’s what explains their energy efficiency, Corporaal says. “An approximation is often good enough, it’s okay to be a bit wrong. It’s also not a problem when we lose a few braincells, there’s enough redundancy – also in the memory function. The human brain has about one hundred billion neurons, each of which has up to ten thousand connections to other neurons; these connections form our memory. That’s why things start to go wrong only after we lose a substantial part of our braincells. How to apply these principles in computers is one of our research areas, in projects centering around ‘approximate computing’.”
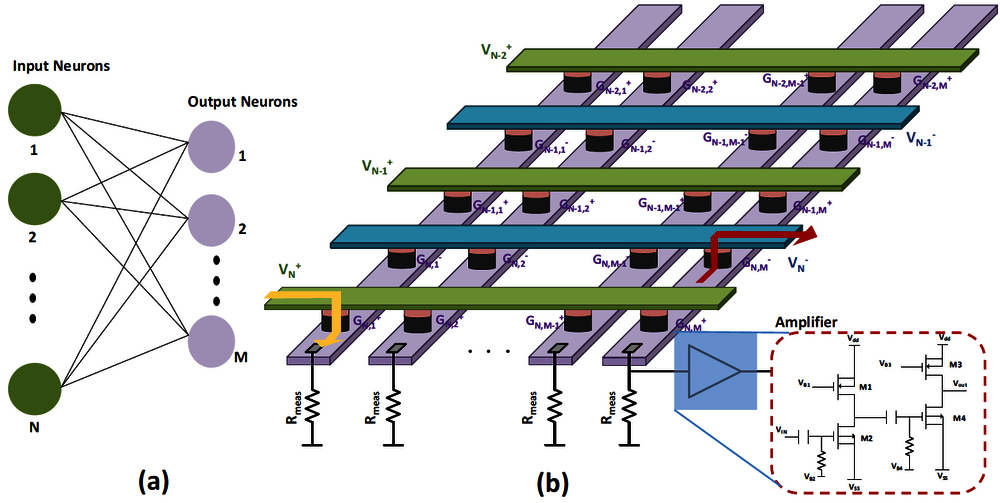
In an effort to simulate the brain, the Electronic Systems group also works on so-called ‘memristors,’ in which small programmable electrical resistors take the role of the memory function. “You can set the conductivity level, in two or more positions.” Memristors in a so-called ‘crossbar array’ configuration allow you to combine the memory and computation functions in the same place in the computer, just like in the brain, Corporaal says. “Then you’re talking about analog components, which you can install in a digital system.”
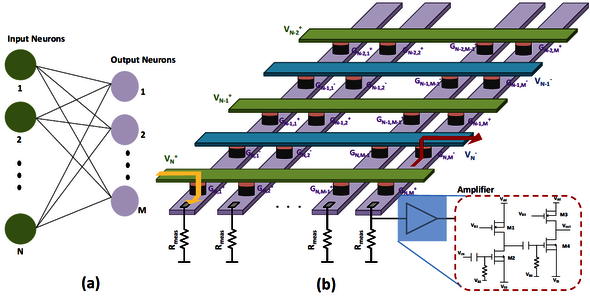
2. Photonic chips

Patty Stabile is assistant professor in the Electro-Optical Communication Systems group (Department of Electrical Engineering) and an expert in the field of photonic chips, in particular for use in neural networks. These are computer chips that use light instead of electrons to process information.
Long-distance digital data transfer mostly takes place nowadays in optical fibers: with light, instead of electrons. Because light allows you to transmit much larger quantities of data with relatively little energy loss, Stabile explains. “Our goal is to work on the integrated chips themselves with light as well, for data transport, but also for the calculations. With the right architecture, you can perform a virtually unlimited number of operations simultaneously on photonic chips; this is because many light beams can be transmitted without the beams interacting. That also means that the energy consumption per operation decreases rapidly with increasing input data rate.”
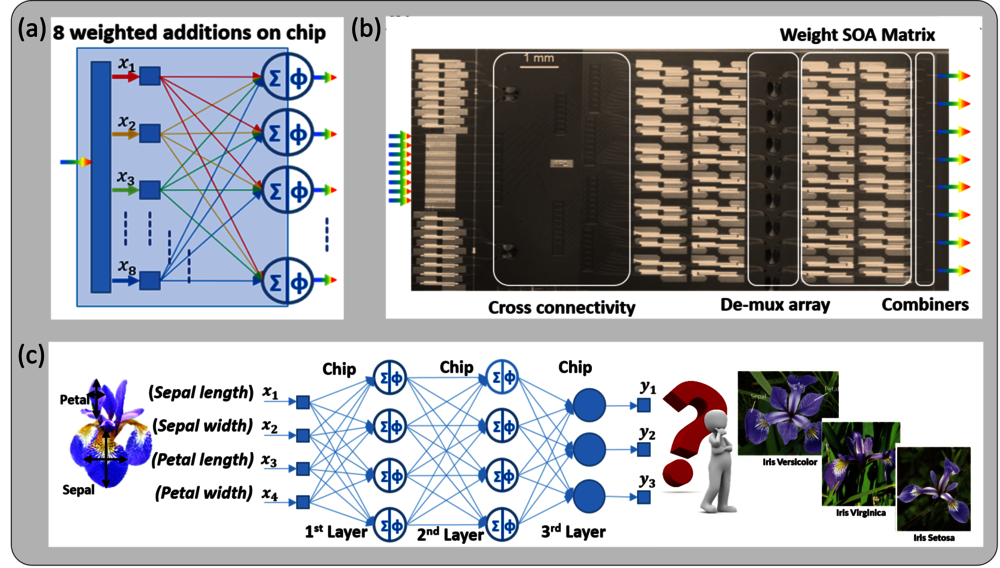
TU/e has been at the global forefront in the field of photonic chips for years. Stabile says that she and her colleagues recently demonstrated an optical neural network – with three layers of eight artificial neurons each – based on an indium phosphide (InP) chip that she had made at TU/e back in 2011 already. “Eight neurons might not sound like much, but we were the first with so many photonic neurons in a single layer. And even with relatively few photonic neurons it’s possible to reach high computing speeds, because signals can be processed simultaneously. We reach eight billion operations per second!”
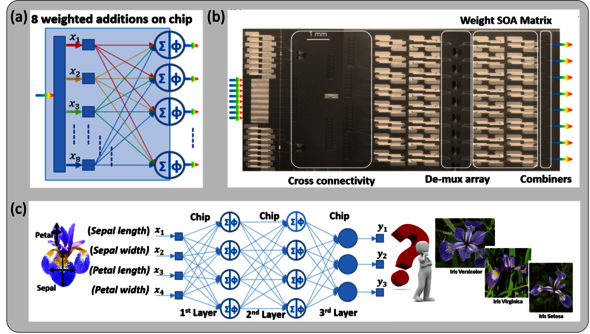
Last year, Patty Stabile and her colleagues showed that you can classify images with such a photonic neural network by applying it to a classic example of classification: classifying images of irises (the flowers) into three categories. It turned out that most errors occurred when the photonic signals switched to electronic signals and vice versa. “That’s why our goal is to keep the calculations in the optical domain as much as possible in order to arrive at a completely optical classification. Unfortunately, ‘training’ the network for that task, which has to take place prior to the image classification, isn’t possible yet with a completely photonic network because no reliable optical memory exists at this point. You can however already combine optical and electronic methods during training.”
Although the experiment’s input consisted of 6-bit digital data, the photonic neural network proved to perform best when these bits were converted into an analog light signal with 64 levels. “Analog works faster, provided that the signals are of sufficient quality,” Stabile explains. “In practice, you might even want to combine digital and analog optical signals in different layers of the network to emulate the complex way our brain works.”
3. Plastic brain
Like Henk Corporaal, Yoeri van de Burgt, assistant professor in the Microsystems section (Mechanical Engineering) works on memristors. However, he uses completely different materials than the usual silicon technology: Van de Burgt experiments with electrically conductive polymers, comparable to the materials that are used to make plastic solar cells and OLED display screens.
“In our brain, the brain cells or neurons are connected via so-called synapses,” he explains. “You could think of a neuron as the computing center, the processor, of our brain, while the synapses have a memory function. That’s because the connection via the synapses becomes stronger when it is used more frequently. Regular communication between certain neurons, as a result of doing something repeatedly or learning something, leads to an electronic highway between those neurons. That is how our memory works.”

Conductive polymers are very suitable for making an artificial variant of neurons, Van de Burgt explains. “They work at very low power levels, and it’s easy to adjust the electrical resistance by adding or removing ions. That already works quite well in a ‘wet’ environment and we are currently working with the Holst Centre to make this scalable in a more practical, ‘dry’ situation as well.” The major advantage of ‘plastic’ synapses is that they are truly analog, he emphasizes. “You can tune the memristors of inorganic materials in a few steps at most, but with conductive materials it’s a continuous scale.”
Van de Burgt thinks his artificial neurons can be applied to labs-on-a-chip for example, where they can be trained to identify and classify certain molecules or cells in blood, saliva or urine. “Their energy efficiency makes them ideally suited for those kinds of stand-alone applications. This way, we want to teach them to identify tumor cells in blood, for example. Or have them determine whether someone has cystic fibrosis based on a sample of sweat.”
The mechanical engineer and his colleagues have also made artificial synapses that respond to dopamine, an important signaling chemical in the natural brain. This will pave the way for applications in the human body, according to Van de Burgt. “You basically have a learning sensor that can be used for ‘advanced prosthetics,’ where the patient learns how to use a prosthesis, such as a forearm, for example. Learning takes place not only in the patient’s brain, but also in the – artificially intelligent – prosthesis. “That way, you make optimal use of the adaptive characteristics of our materials, and of the fact that they’re biocompatible.”

4. DNA computer

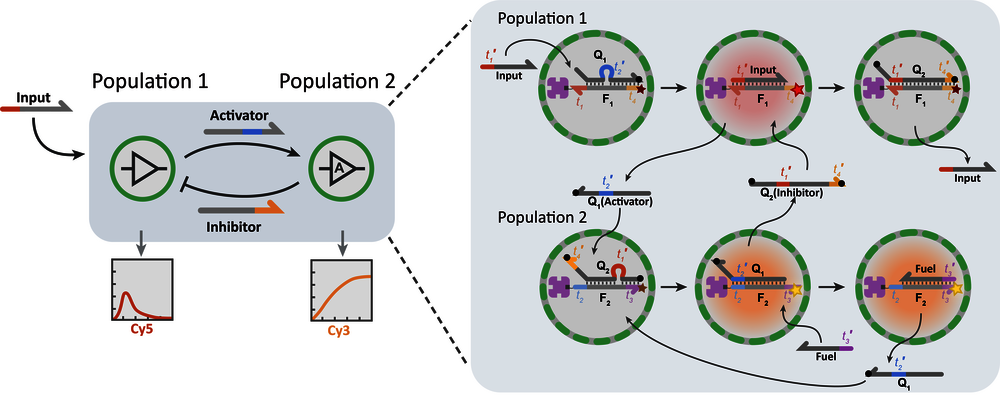
If there is one material that’s compatible with living systems – biocompatible, as Van de Burgt puts it – is has to be DNA, the molecule that contains the code of life itself. But it will come as a surprise to many that DNA can also be used for artificial intelligence. Still, that is what Tom de Greef, associate professor of Synthetic Biology, envisages. “There already are neural networks based on DNA that are able to classify molecular patterns. At Caltech they have even managed to create a learning neural network out of DNA.”
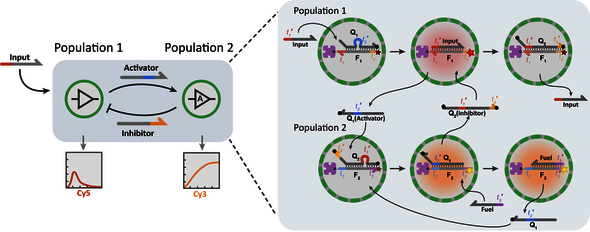
Programming DNA responses
Simply put, DNA molecules consist of chains of four different molecules, so-called bases, indicated with C, G, A, and T: the letters in which our genetic information is encoded. Since the C and the G as well as the A and the T form pairs, two strains with the right – complementary – base order can be zipped together so to speak. This way, the base order of strings determines with which other DNA molecules they can react. That allows you to program the desired responses, comparable to writing software.
Obviously, DNA computing can be especially useful in the biomedical domain, De Greef emphasizes. “Many disorders can be detected in blood using microRNA.” DNA can bind to these short pieces of genetic code, and this sets a kind of chain reaction in motion leading to an outcome: sick or not sick. “You often need to look at several variants of microRNA for a diagnosis, and this requires a lot of different actions. You need to read values, enter them into a computer and run an algorithm. With a DNA computer this can all be done in just one step, in the blood itself; this saves a lot of work. It’s possible already to detect certain diseases with a DNA computer. It’s not accurate enough, but there are quite a few possibilities already.”
DNA can also be used to store large amounts of data. “That is a very recent development, but it is almost more economical already than magnetic storage in datacenters. You simply translate the binary data into a DNA code, let that DNA synthesize and subsequently freeze dry. A few grams of DNA can carry all the information from an entire datacenter. And you can read the data by ‘sequencing’ the DNA.” This is a very promising solution, in particular for archives containing information that doesn’t need to be accessed regularly, according to Van de Greef. “It hardly costs energy compared to magnetic storage.”
Chronic conditions
The holy grail of DNA computing is combining the computing with data storage in the form of DNA. De Greef has a few ideas about that. “I think you could use CRISPR-Cas for that. That would allow you to store and read a molecular history of the DNA computer’s operations, as it were. That could be handy for monitoring chronic conditions, for example.” Last year, he and his colleagues found casings to protect DNA computers against enzymes that would otherwise cause problems, “Those casings combined with a mechanism to store information allows you to do wonderful things,” he says enthusiastically.
5. Quantum computer
Naturally, a story about revolutionary computers wouldn’t be complete without the quantum computer. The expert in this field in Eindhoven is Erik Bakkers, professor at Advanced Nanomaterials & Devices. His nanowires may well form the building blocks for a quantum computer based on Majorana particles, he and colleagues from Delft showed. According to Bakkers, quantum computers undoubtedly feature in the plans for artificial intelligence of tech giants like Google, Microsoft and IBM. The applications will however be very specific, he believes.
“Quantum computers certainly aren’t better at processing larger amounts of information; it’s not easy to read that data. At this point, they only function at extremely low temperatures, which is why you need a large device with a cryostat. Mobile applications are unlikely for that reason. Simply put, quantum computers are especially good at quantum mechanical problems: calculating large molecules for example, and perhaps even viruses, for drug development.”

In addition, quantum computers are supposedly good at cracking safety encryptions and searching specific types of databases. The algorithms that were designed for that purpose make use of the parallel character of quantum computers: the fact that each bit isn’t a ‘0’or a ‘1,’ but a kind of sum of both. This makes it possible to make simultaneous calculations of all input, which saves a lot of time and energy with quantum computers that have a large number of ‘qubits.’ “Compared to datacenters that use hundreds of megawatts, a quantum computer with a cryostat of 10 kilowatts is obviously extremely energy efficient.”

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
All in all, Bakkers is fairly skeptical about the possibilities of quantum computers in the short term. “Google is furthest along with their project, they have about fifty qubits. But these qubits aren’t stable and need a million other qubits each for support in order to function. They are by no means there yet, and it will also take some time before we will be able to build a Majorana-based computer. The progress, however, has accelerated due to the current hype surrounding quantum computers, simply because more and more people are working on this problem.”
EAISI
TU/e invests big in artificial intelligence: last summer, it was announced that the newly established Eindhoven Artificial Intelligence Systems Institute (EAISI) will recruit fifty new researchers, on top of the hundred researchers already working in this field. The university intends to invest a total sum of a about one hundred million euro’s, which includes turnover from the government’s sector funds and the costs of the renovation of the Laplace building, which is to become the permanent location for EAISI, currently located in the Gaslab.
Discussion